Jenkinspipeline脚本编写实践分享(一)上篇
持续集成的实践应用已经在很多公司里推行,其中主流的持续集成工具就是Jenkins,作为过去两年多来一直致力于公司的持续集成部署的我,回身看到踩过的不少坑,感慨不已,所以决定将这些做个记录。
刚开始在公司部署Jenkins服务,使用的是插件流的方式部署,部署一个job要关联到十几个插件(插件流的方式就不在这里赘述了,网上也有很多资料),两个月后我把部署方式改成了Jenkins推荐的pipeline脚本的方式,这也是响应Jenkins2.0的精髓Pipeline as Code。
Jenkins的pipeline有Declarative Pipeline(在Pipeline 2.5中引入,结构化方式)和Scripted Pipeline两种方式编写,我选择的是Declarative Pipeline的写法,入门简单。
好了话不多说,直接上实例:
!/usr/bin/env groovypipeline{//确认使用主机/节点机agentany/*{node { label master}}*/// 声明参数parameters{//SVN代码路径string(name:repoUrl,defaultValue:http://svn.com/svn/server/job,description:SVN代码路径)// 部署内容的相对路径string(name:deployLocation,defaultValue:target/*.jar,target/alternateLocation/*.*,+target/classes/*.*,target/classes/i18n/*.*,target/classes/rawSQL/*.*,+target/classes/rawSQL/mapper/*.*,target/classes/rawSQL/mysql/*.*,+target/classes/rawSQL/sqlserver/*.*,description:部署内容的相对路径)//服务器参数采用了组合方式,避免多次选择string(name:dev_server,defaultValue:IP,Port,Name,Passwd,description:开发服务器(IP,Port,Name,Passwd))string(name:ZHtest_server,defaultValue:IP,Port,Name,Passwd,description:中文测试服务器(IP,Port,Name,Passwd))string(name:alT19_server,defaultValue:IP,Port,Name,Passwd,description:生产服务器T1(IP,Port,Name,Passwd))string(name:alT20_server,defaultValue:IP,Port,Name,Passwd,description:生产服务器T2(IP,Port,Name,Passwd))}// 声明使用的工具tools{mavenmavenjdkjdk1.8}//常量参数,初始确定后一般不需更改environment{// SVN服务全系统只读账号cred_id【参数值对外隐藏】CRED_ID=CRED_ID//项目经理邮箱地址PM_EMAIL=PM// Jenkins负责人JM_EMAIL=QA//测试人员邮箱地址【参数值对外隐藏】TEST_EMAIL=Tester}triggers{pollSCM(H/5 * * * 1-5)}//pipeline运行结果通知给触发者post{//执行后清理workspacealways{echo"clear workspace......"deleteDir()}failure{script{emailextbody:${JELLY_SCRIPT,template="static-analysis"},recipientProviders:[[$class:RequesterRecipientProvider],[$class:DevelopersRecipientProvider]],subject:${JOB_NAME}- Build ${BUILD_NUMBER} - Failure!}}}stages{stage(清理本地仓库){steps{sh"/home/jenkins/del_lastUpdated.sh"}}stage(Checkout){steps{script{//从SVN拉取代码defscmVars=checkout([$class:SubversionSCM,additionalCredentials:[],excludedCommitMessages:,excludedRegions:,excludedRevprop:,excludedUsers:,filterChangelog:false,ignoreDirPropChanges:false,includedRegions:,locations:[[credentialsId:CRED_ID,depthOption:infinity,ignoreExternalsOption:true,local:.,remote:params.repoUrl]],workspaceUpdater:[$class:UpdateUpdater]])svnversion=scmVars.SVN_REVISION}//sh "echo ${svnversion}"}}// 编译构建代码stage(构建){steps{// maven构建sh"mvn -Dmaven.test.failure.ignore clean install"}}stage(静态检查){steps{echo"starting codeAnalyze with SonarQube......"//sonar:sonar.QualityGate should passwithSonarQubeEnv(Sonar-6.4){//固定使用项目根目录${basedir}下的pom.xml进行代码检查//sh "mvn -f pom.xml clean compile sonar:sonar"sh"mvn sonar:sonar "+"-Dsonar.sourceEncoding=UTF-8 "//+//"-Dsonar.language=java,groovy,xml"+//"-Dsonar.projectVersion=${v} "+//"-Dsonar.projectKey=${JOB_NAME} "+//"-Dsonar.projectName=${JOB_NAME}"}script{// 未通过代码检查,中断timeout(10){//利用sonar webhook功能通知pipeline代码检测结果,未通过质量阈,pipeline将会faildefqg=waitForQualityGate()if(qg.status!=OK){error"未通过Sonarqube的代码质量阈检查,请及时修改!failure: ${qg.status}"}}}}}stage(归档){steps{// 归档文件/*archiveArtifacts artifacts: target/*.jar,target/alternateLocation/*.*,+target/classes/*.*,target/classes/i18n/*.*,target/classes/rawSQL/*.*,+target/classes/rawSQL/mapper/*.*,target/classes/rawSQL/mysql/*.*,+target/classes/rawSQL/sqlserver/*.*,fingerprint: true*/archiveArtifactsparams.deployLocation}}stage(部署到开发环境){steps{//根据param.server分割获取参数,包括IP,jettyPort,username,passwordscript{defdev_split=params.dev_server.split(",")dev_serverIP=dev_split[0]dev_serverPort=dev_split[1]dev_serverName=dev_split[2]dev_serverPasswd=dev_split[3]}echoDeploying to dev_server//清理清理旧程序sh"/home/jenkins/del_158_client.sh bas"// 部署到开发环境sh"scp -r target/*.jar ${dev_serverName}@${dev_serverIP}:/jenkins/datacenter/bas/"sh"scp -r target/alternateLocation ${dev_serverName}@${dev_serverIP}:/jenkins/datacenter/bas/"sh"rsync -av target/classes/ --exclude=com ${dev_serverName}@${dev_serverIP}:/jenkins/datacenter/bas/"// 重启服务sh"/home/jenkins/kill_158_client.sh bas-job bas"}}stage(开发环境接口自动化测试){agent{labelSlave_Linux_69_2}steps{sh"sleep 60s"echo"starting interfaceTest......"/*echo 节点是: ${env.NODE_NAME}echo 节点是: ${env.NODE_LABELS}echo ${currentBuild}echo ${env}echo " 当前BuildId: ${env.BUILD_ID}"*/dir(/home/jenkins/pm_test){sh(source /etc/profile;newman -c APD201test_bas.postman_collection.json)}}}stage(对当前版本代码打tag){steps{timeout(5){script{inputmessage:需要打tag嘛?}}//sh "echo ${params.repoUrl}"//sh "echo ${svnversion}"sh"/home/jenkins/del_crea_tag.sh bas-job ${params.repoUrl} ${svnversion}"}}stage(确认是否部署到测试环境){steps{timeout(5){script{mailto:"${JM_EMAIL} ${PM_EMAIL}",subject:"PineLine ${JOB_NAME} (${BUILD_NUMBER})人工验收通知",body:"提交的PineLine ${JOB_NAME} (${BUILD_NUMBER})进入人工验收环节\n请及时前往${env.BUILD_URL}进行测试验收"inputmessage:部署到测试环境?//,submitter:"${PM_EMAIL}"// 中文环境defZHtest_split=params.ZHtest_server.split(",")ZHtest_serverIP=ZHtest_split[0]ZHtest_serverPort=ZHtest_split[1]ZHtest_serverName=ZHtest_split[2]ZHtest_serverPasswd=ZHtest_split[3]}}//中文测试环境//清理清理旧程序sh"/home/jenkins/del_32_client.sh bas"// 部署到中文测试环境sh"scp -r target/*.jar ${ZHtest_serverName}@${ZHtest_serverIP}:/jenkins/datacenter/bas/"sh"scp -r target/alternateLocation ${ZHtest_serverName}@${ZHtest_serverIP}:/jenkins/datacenter/bas/"sh"rsync -av target/classes/ --exclude=com ${ZHtest_serverName}@${ZHtest_serverIP}:/jenkins/datacenter/bas/"}}stage(部署到测试环境){steps{echoDeploying to ZHtest_server// 重启服务sh"/home/jenkins/kill_32_client.sh bas-job bas"}}stage(测试环境接口自动化测试){agent{labelSlave_Linux_69_2}steps{//sh "sleep 60s"echo"starting interfaceTest......"dir(/home/jenkins/pm_test){sh(source /etc/profile;newman -c API_test.json)}}}stage(是否发布到生产环境?){steps{timeout(10){script{mailto:"${JM_EMAIL} ${PM_EMAIL}",subject:"PineLine ${JOB_NAME} (${BUILD_NUMBER})发布生产环境通知",body:"提交的PineLine ${JOB_NAME} (${BUILD_NUMBER})进入生产环境部署\n请及时前往${env.BUILD_URL}进行确认"inputmessage:部署到生产环境?,submitter:"${PM_EMAIL}"// 中文环境defZHtest_split=params.ZHtest_server.split(",")ZHtest_serverIP=ZHtest_split[0]ZHtest_serverPort=ZHtest_split[1]ZHtest_serverName=ZHtest_split[2]ZHtest_serverPasswd=ZHtest_split[3]// 英文环境defUStest_split=params.UStest_server.split(",")UStest_serverIP=UStest_split[0]UStest_serverPort=UStest_split[1]UStest_serverName=UStest_split[2]UStest_serverPasswd=UStest_split[3]}}//文件服务环境//清理清理旧程序sh"/home/jenkins/del_file_client.sh bas"sh"scp -r target/*.jar ${file_serverName}@${file_serverIP}:/data/datacenter/bas/"sh"scp -r target/alternateLocation ${file_serverName}@${file_serverIP}:/data/datacenter/bas/"sh"rsync -av target/classes/ --exclude=com ${file_serverName}@${file_serverIP}:/data/datacenter/bas/"}}stage(部署生产环境){parallel{stage(中文环境){steps{//sh "sleep 60s"echo"starting Deploy Chinese_Server......"}}stage(英文环境){steps{//sh "sleep 60s"echo"starting Deploy English_Server......"}}}}}}一段段的来解释
//确认使用主机/节点机agent any /*{node { label master}}*/
就如注释所写的,这里是选择要使用的Jenkins服务器,开始之初配置了两台,1台作为主机master,另一台作为从节点69_2,而any表示的是所有节点中任何一台,这是会根据Jenkins内部的分配机制分配的,如果指定是哪个节点执行脚本就是用注释里的方法,当然还有其他方式也可以指定。
// 声明参数parameters{//SVN代码路径string(name:repoUrl, defaultValue:Job Board - SVN International Corp., description: SVN代码路径)// 部署内容的相对路径string(name:deployLocation, defaultValue: target/*.jar,target/alternateLocation/*.*,+target/classes/*.*,target/classes/i18n/*.*,target/classes/rawSQL/*.*,+target/classes/rawSQL/mapper/*.*,target/classes/rawSQL/mysql/*.*,+target/classes/rawSQL/sqlserver/*.*, description: 部署内容的相对路径 )//服务器参数采用了组合方式,避免多次选择string(name:dev_server, defaultValue: IP,Port,Name,Passwd, description: 开发服务器(IP,Port,Name,Passwd))string(name:ZHtest_server, defaultValue: IP,Port,Name,Passwd, description: 中文测试服务器(IP,Port,Name,Passwd))string(name:alT19_server, defaultValue: IP,Port,Name,Passwd, description: 生产服务器T1(IP,Port,Name,Passwd))string(name:alT20_server, defaultValue: IP,Port,Name,Passwd, description: 生产服务器T2(IP,Port,Name,Passwd))}
接下去这段是参数声明,格式都是以string形式来声明string(name:参数名, defaultValue: 默认值, description: 备注),当然参数也有其他形式,这里只用到这个。这个脚本里声明了SVN地址、归档的部署的文件、部署服务器地址参数。
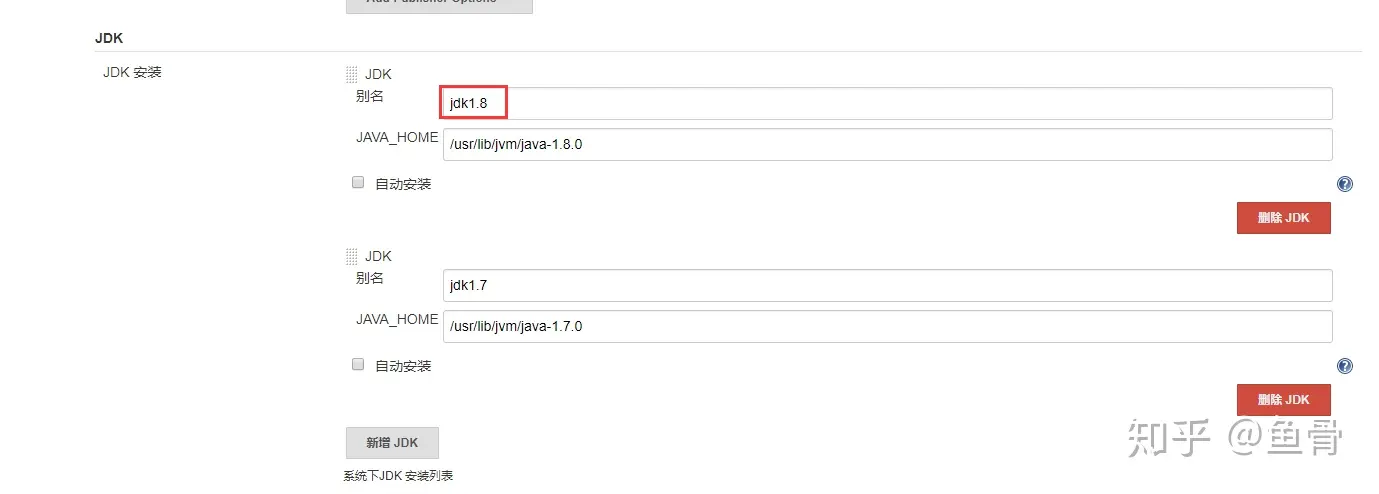
// 声明使用的工具tools {maven mavenjdk jdk1.8}
这段是说的当前job里会用到的工具,因为当前脚本是编译maven工程的,所以使用了JDK和maven,引号中的名字是Jenkins全局工具配置里设定好的
//常量参数,初始确定后一般不需更改environment{// SVN服务全系统只读账号cred_id【参数值对外隐藏】CRED_ID=CRED_ID//项目经理邮箱地址PM_EMAIL=PM// Jenkins负责人JM_EMAIL=QA//测试人员邮箱地址【参数值对外隐藏】TEST_EMAIL=Tester}
这一段是常量的声明,比如拉取SVN代码时需要的账号cred_id、需要发送邮件对象的邮件地址等等,账号cred_id可以通过Jenkins提供的工具得到,后面段落的解读会说明。
triggers {pollSCM(H/5 * * * 1-5)}
定时器,顾名思义,这部分是设定定时启动的,pollSCM表示的是定时检查代码库的变化,如果有变化触发该job的构建;而cron则表示定时触发该job的构建,里面的规则如下:
MINUTE HOUR DOM MONTH DOW
MINUTE 一小时内多少分钟(0-59)
HOUR 一天内多少小时(0-23小时)
DOM 一个月内多少天(1-31)
MONTH 每月(1-12)
DOW 星期几(0-7),其中0和7都表示周日。
如果要指定一个字段允许多个值,就按下面提供的操作步骤(指定)。
优先顺序如下:
* 可用来指定所有有效的值。
M-N 可以用来指定一个范围,比如1-5
M-N/X或*/X 可用于在指定范围内跳跃一个X的值,比如在MINUTE字段中"*/15"表示"0,15,30,45","1-6/2"表示"1,3,5"。
A,B,...,Z 可以用来指定多个值,比如0,30或1,3,5。
任何空白行和开始的行都将表示为注释而不予理睬。
此外,@yearly, @annually, @monthly, @weekly, @daily, @midnight, @hourly都是支持的
举些例子:
* * * * * 每分钟
5 * * * * 每一小时后第5分钟
H/15 * * * * 每15分钟
H(0-29)/10 * * * * 每小时的0到29分钟每15分钟
H 2-19/2 * * 1-5 每周1到周五(工作日)2点到19点每2小时执行
H H 1,15 1-11 * 1到11月1号和15号各执行一次
//pipeline运行结果通知给触发者post{//执行后清理workspacealways{echo "clear workspace......"deleteDir()}failure{script {emailext body: ${JELLY_SCRIPT,template="static-analysis"},recipientProviders: [[$class: RequesterRecipientProvider],[$class: DevelopersRecipientProvider]],subject: ${JOB_NAME}- Build ${BUILD_NUMBER} - Failure!}}}
post部分是在整个构建都执行完之后再执行,这里主要是一些收尾工作,always表示始终执行,这里是清除workspace下的对应的工程目录;failure表示当失败的时候需要执行的动作,这里写的是给手动触发人员和提交代码的开发人员发送失败邮件通知。
stage(清理本地仓库) {steps{sh "/home/jenkins/del_lastUpdated.sh"}}
从这里开始才是构建过程的第一个stage,这个stage里我首先执行的是清理本地仓库中更新失败的文件,第一步首先执行这个主要是因为之前踩过这个坑,因为是Jenkins在构建maven工程时会去下载该工程所依赖的各种jar包,同时也会从服务器去更新这些jar包,但由于网络环境的问题,有些jar包更新会失败,会留下后缀名为.lastUpdated残留文件,当job构建的时候就会卡在这里,所以后来写了个删除此类文件的shell脚本放在服务器上,每次构建maven工程的时候都会首先调用这个脚本删除残留文件。该shell脚本内容如下:
!/bin/bash本地仓库的地址del_path="/home/jenkins/.m2/repository/"find $del_path -name *.lastUpdated -print |xargs rm -fecho "是否还有残留"find $del_path -name *.lastUpdated -print
在这里也非常感谢运维的同事,在pipeline脚本中用到的shell脚本是由我们的运维小哥协助我完成的,再次感谢我们的运维小哥。
stage(Checkout) {steps {script {//从SVN拉取代码def scmVars = checkout ([$class: SubversionSCM,additionalCredentials: [],excludedCommitMessages: ,excludedRegions: ,excludedRevprop: ,excludedUsers: ,filterChangelog: false,ignoreDirPropChanges: false,includedRegions: ,locations: [[credentialsId: CRED_ID,depthOption: infinity,ignoreExternalsOption: true,local: .,remote: params.repoUrl]],workspaceUpdater: [$class: UpdateUpdater]])svnversion = scmVars.SVN_REVISION}//sh "echo ${svnversion}"}}
这一stage就是代码库去拉取代码,我们使用的是SVN,拉取SVN的语句有点长,不用担心,这其实是通过Jenkins提供的工具生成出来的,这个工具就是Pipeline Syntax,在Jenkins左边的菜单上有
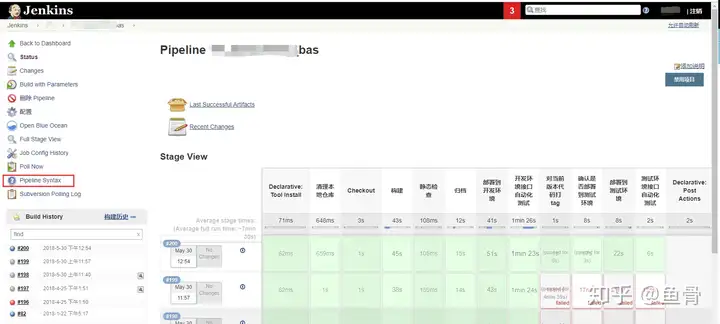
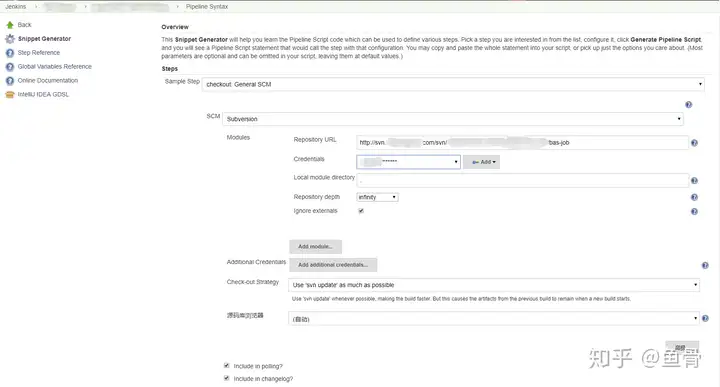

Sample Step:选择 checkout:General SCM 这里可以选择很多步骤,,具体可以参考Jenkins自带的说明;
SCM 选择Subversion
Repository URL:这里输入的是拉取代码的地址
Credentials:这是拉取代码所用的账号,需要先期在Jenkins的credentials里添加好
其他内容都默认就行了。然后选择屏幕下方按钮 Generate Pipeline Script,就会生产我们刚刚看到的那段内容,因为是没有格式的,看的不爽的同学可以自行整理,这里的SVN地址和credentialsId我都做了参数变量的定义,在上面都以提到过,这样以后的脚本只要替换这两个就可以编译其他的maven工程了。
细心的朋友会发现拉取代码的脚本中还多了一段svnversion = scmVars.SVN_REVISION这段是去提取拉取代码的SVN版本号,这是为了在之后对代码打标签使用,如何在pipeline中获取SVN的版本我也是花了好久才在国外的Jenkins论坛上找到的方法,pipeline的使用的分享在国内不是特别多,主要都是一些基本语法的介绍,实用的不多,pipeline的自由度比较高,很多设想的步骤都因为没有资料而不得不放弃了。
后面篇幅不够了,请转《Jenkins pipeline脚本编写实践分享(一)下篇》
使用Pipeline构建
新建一个Pipeline项目,写入Pipeline的构建脚本,如下图所示:
对于单个项目来说,使用这样的Pipeline来构建能够满足绝大部分需求,但是这样做也有很多缺陷,包括:
- 多个项目的Pipeline打包脚本不能公用,导致一个项目写一份脚本,维护比较麻烦。一个变动,需要修改多个job的脚本;
- 多个人维护构建job的时候,可能会覆盖彼此的代码;
- 修改脚本失败以后,无法回滚到上个版本;
- 无法进行构建脚本的版本管理,老版本发修复版本需要构建,可能和现在用的job版本已经不一样了,等等。
把Pipeline当代码写
既然存在缺陷,我们就要找更好的方式,其实Jenkins提供了一个更优雅的管理Pipeline脚本的方式,在配置项目Pipeline的时候,选择Pipeline script from SCM,如下图所示:
这样,Jenkins在启动job的时候,首先会去仓库里面拉取脚本,然后再运行这个脚本。在脚本里面,我们规定的构建方式和流程,就会按部就班地执行。构建的脚本,可以实现多人维护,还可以Review,避免出错。 以上就算搭建好了一个基础,而针对多个项目时,还有一些事情要做,不可能完全一样,以下是构建的结构图:
Jenkins的Pipeline脚本在美团餐饮SaaS中的实践