ChatGPT:GPT-1核心技术
GPT(Generative Pre-training Transformer)于2018年6月由OpenAI首次提出,论文是《Improving Language Understanding by Generative Pre-Training 》。GPT-1基于Transformer解除了顺序关联和依赖性的前提,采用生成式模型方式,重点考虑了从原始文本中有效学习的能力,这对于减轻自然语言处理( NLP )中对监督学习的依赖至关重要;该模型和论文的发布,标志着大规模语言模型的开发取得了重大突破。
GPT-1的设计是为了解决如何利用容易获取的大规模无标注数据来为模型的训练所用的问题,这是NLP的一个基本挑战。传统的NLP模型依赖于手工特征和统计方法来处理语言。然而,这些方法在处理复杂的语言结构方面存在局限性,并需要大量的人力工作进行特征工程,代价非常昂贵。为了克服这些限制,GPT-1使用了一种无监督的预训练技术,称为基于Transformer的生成式预训练。该技术将模型训练为根据前面的单词预测句子中的下一个单词。通过在大量无标注的文本数据上预训练模型,GPT-1能够学习到一种全面的语言结构和上下文表示,使其能够执行各种与语言相关的任务。
GPT-1解决的另外一个主要问题就是,如何让模型支持多任务(泛化为通用任务)。在完成无监督的预训练,GPT-1利用有标注的数据进行fine-tuning,实现了泛化的能力,也就是能够在没有任何任务特定训练的情况下执行各种NLP任务。例如,GPT-1能够生成连贯且语法正确的文本、根据给定上下文回答问题,并对文本数据进行情感分析。该模型理解和生成人类语言的能力得到了广泛赞扬,成为与语言相关研究的热门选择。
GPT-1 提出的两步走的训练方法成为大模型最佳工程实践,和之前Google提出的Word2Vec相比,可以解决更大规模数据模型问题。
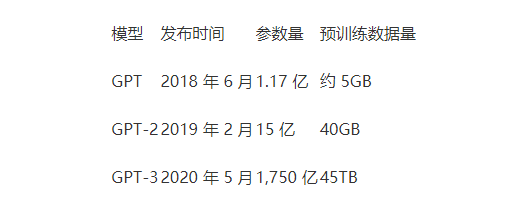
GPT-1是一种基于Transformer的语言模型,具有1.17亿个参数,使其成为当时最大的语言模型之一。GPT-1的架构,对Transformer进行了显著简化,仅使用解码器部分,由12个变压器解码器层组成,每个层具有768个隐藏单元和12个自注意头。该模型在多种文本数据上进行训练,包括新闻文章、书籍和网页。
尽管具有许多优点,但GPT-1也存在一些限制。其中一个主要挑战是不同语言领域之间缺乏知识迁移的问题。例如,该模型可能难以在需要特定领域的知识(例如科学或技术语言)的任务上表现良好。此外模型的大小和计算复杂性使其难以在资源受限设备上进行训练和部署,从而限制了其在某些情境下的实际应用。
GPT-1代表了大规模语言模型发展的一个重要里程碑,并为之后更强大的模型(如GPT-2和GPT-3)的开发奠定了基础。其基于Transformer的生成式预训练技术、大规模架构和能够在没有任务特定训练的情况下执行各种语言任务的能力,使其成为NLP研究中的有价值工具。虽然该模型存在一些限制,但其对NLP领域的贡献不言而喻,并且在人工智能研究历史上仍然是一个重要的里程碑。

Pre AGI 时代的第一场大型舆论「闹剧」。
马斯克和「深度学习三巨头」之一的 Bengio 等一千多位学界业界人士,联名呼吁叫停 AI 大模型研究的新闻,刷屏网络,掀起轩然大波。

GPT 的研究会被叫停吗?在学界业界看来,AI 真的会对人类产生威胁吗?这封联名信是证据凿凿的警示还是徒有恐慌的噱头?支持者、反对者纷纷表态,吵作一团。
在混乱中,我们发现,这份联名信的真实性和有效性都存在问题。很多位列署名区的人们,连他们自己都不知道签署了这封联名信。
另一方面,联名信本身的内容也值得商榷,呼吁人们重视 AI 安全性的问题当然没错,可叫停 AI 研究 6 个月,甚至呼吁政府介入,等待相关规则、共识的制定。这种天真且不切实际的做法,在科技发展的历史上实属少见。
与此同时,不少人发现,OpenAI 开放了一批 GPT-4 API 的接口申请,开发者们正兴奋地想要将这轰动世界的技术成功应用在他们的产品中。Pre AGI 时代的序幕,已经缓缓拉开。
AI 会停下来吗?AI 能停下来吗?