理解人类语言:电脑AI写作原理,神经网络语言模型的运作(1)
在本系列中,我将尽可能通俗易懂地,深入讲述电脑 AI 的写作原理(包括细节)。
人类写作,有想法,有写作目标,可能还有提纲,有整体结构的构思。然后,用语法和修辞表述出来。
电脑写作,最常见的方法是,一个个字写。每次分析一遍前文,然后在后面添一个字。
一、电脑的写作过程
在电脑眼中,写作是个数学问题。
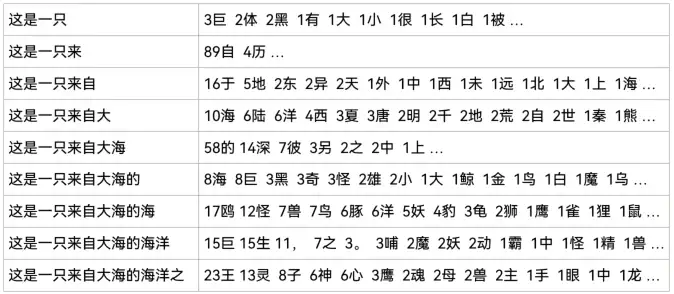
举例,输入这是一只,然后让电脑续写,它的写作过程如下:
电脑的思维模型,是一个神奇函数 F(C),输入前文 C,输出下一个字的概率分布。
电脑的写作过程:
- 电脑计算 F(这是一只) = 3%巨,2%体,2%黑,1%有,1%大,… 电脑按照概率分布,决定下一个字选择来。
- 电脑计算 F(这是一只来) = 89%自,4% 历,… 电脑按照概率分布,决定下一个字选择自。
- 电脑计算 F(这是一只来自) = 16%于,5% 地,… 电脑按照概率分布,决定下一个字选择大。
注意:按照概率分布决定的意思是,按照这个分布随机选择。例如,这是一只后面,有3%的概率选巨,2%的概率选体(而不是每次直接选概率最高的字,因为那样出来的内容很容易重复)。所以,同样的开头,电脑每次续写的结果都会千变万化。
于是,电脑可以一个个字写下去,写出任意长的内容。
如果你仔细看,会发现这个电脑有时计算的概率不准(例如这是一只来自大海的海洋后面逗号和句号的概率过高),因为它是个小模型,它对于中文的理解还不够准确。
我训练的 AI 写作模型是开源的,可以在这里下载(需要电脑):
还有一个网页版,在手机点开就能写(不过比电脑版弱一些):
那么,电脑是如何计算出这个神奇函数 F(C)?
首先,将所有字符(汉字、标点、数字、外语、符号等等)都编码成数字。
我的模型有一个固定的字符表,支持 8849 种字符(可以支持更多,但越大运行越慢,所以八千多够用了):

所以这是一只会变成【7587, 3482, 605, 1372】。
然后 F(7587, 3482, 605, 1372) 会计算出 8849 个概率,对应下一个字的概率分布。
例如巨在字表是 2565,F(7587, 3482, 605, 1372) 输出的第 2565 个概率是 0.0375。所以这是一只下一个字是巨的概率是 3.75%。
例如体在字表是 824,F(7587, 3482, 605, 1372) 输出的第 824 个概率是 0.0234。所以这是一只下一个字是体的概率是 2.34%。
总之,这个神奇函数 F(C) 是一个纯粹的数学函数,输入一串数字(代表前文),输出 8849 个概率(代表下一个字的概率分布)。
所以,在电脑看来,写作不应该在语文课教,应该在数学课教。它做几亿次加减乘除之类,就可以算出来怎么写。
二、寻找神奇函数
现在让我们想想,怎么构造 F(C)。
概率分布,需要满足两个条件:(1) 每个字的概率在 0 到 1 之间。(2) 所有 8849 个概率加起来等于 1。
最简单的 F(C),是忽略前文,直接输出 [1/8849, 1/8849, 1/8849, …],意思是,下一个字是在 8849 个字中随机均匀选择。
这样生成的内容是纯乱码,例如:
这是一只嚯穑泫跺罔T贼谅僖溯啪泌坊堆孑蓟刭Yh窦吶剃散恨綮沄势晔偃H鎏镀k蒋赍扈峒哝幄蛴守嶷呓蟮亡蟆圃蟥驼蜮铤蹚《仟憨犀衍蔌拼捕恋沮咦鲞颤莉昃仕蔌飞芪°稍已织媲刿瞥理霍筛苡哞搏瞿惯盔栎窝厅骠眯禄褔儛咆鏖漉峁
稍微聪明一点的 F(C),是注意到每个字符的基础概率不同,例如【无】比【戊】常用。
所以,我们预先扫描一遍小说库,统计 8849 字符各自的出现概率。
然后,F(C) 忽略前文,每次输出 8849 个固定的概率,对应它们的基础概率。(这个方法的学名叫做 1-gram 模型)
这样生成的内容好一些,例如:
这是一只,有!,人身下王光概?带下了们等身后问然来论里知都,不的得色,以说的我源,兰!回还幽期黑力记芊好备奔眼心因被共进现色消立想让眼了身。她间,意仔,成已而,沿出黑临下这还么虽终奇身的的许英东里
再聪明一些的 F(C),是看前文 C 的最后一个字。因为这个字,离下一个字最近,对于下一个字的影响很强。
这其实就是马尔可夫链的思维。(这个方法的学名叫做 2-gram 模型)
我们预先扫描一遍小说库,统计每个字后面各个字的概率。
例如,我后面各个字符的概率是:【12.5% 们 6.7% 的 2.8% , 2.6% 不 …】
例如,只后面各个字符的概率是:【24.3% 是 13.0% 有 8.2% 要 8.0% 能 ...】
然后,每次 F(C) 会根据 C 的最后一个字,输出它后面各个字的概率分布。
这样生成的内容又好一些,开始出现一些词语(因为词语就是常常一起出现的字),例如:
这是一只是技术的手上来找一挥了一定风筝境,我的清楚,停,就是袁督和黑的人都被肚腹,你再踹在水晶的小的走到是在克,便向蝶叶归来就能让他对摩再次子!圣与周桓真当最先隐藏在四大的愚蠢的态:一件事业开阔的贵被黄
三、采样技巧
为了提高通顺度,我们还可以用更保守的采样方式。例如,忽略概率很低的候选字。
每次只考虑概率最高的 20 个候选字(这个方法的学名叫做 top-k 采样):
这是一只是他们这道:他说不那天没有也不到了一声,一个人中人,我们看看到我一个大。是,就要有心的。那么的时没有这么那就不,他们的,我一个时面对不想要我不得子也是你来,我一个人不要,天之间过去。她
每次把所有的候选字排序,然后只在概率位于最前 70% 的候选字中选择(这个方法的学名叫做 top-p 采样):
这是一只是第一个字。我就不能反应该可以气。我,与江海身来说:我就这事!她什么人!我一个人,我们的水的不得?正和多少女的子不是见不会了!他又何不住,看?我的双手,只是跟着我无法行道:没人你
这些保守的采样方式,可以提高一些通顺度,代价是牺牲一些多样性。通常 top-p 的效果较好。
四、多看几个字
现在,你可能会想,我们可以再看前文的最后两个字,看前文的最后三个字,等等。
- 例如,如果电脑仅仅看到只这一个字,后面的字通常是是 有 要 能等等。
- 但是,如果电脑可以看到一只这两个字,那么,它分析小说库中所有出现一只的情况,就知道,后文通常应该接描述动物的形容词(因为作为小说,直接接名词会有些生硬)。
所以,即使只看最后两个字,也足以显著提高效果。
但是,这种方法,即使看再多字,也容易遇到瓶颈:
- 小说库,不可能包括所有可能的n个字组合,写着写着就会遇到我们从来没见过的组合。
- 一种解决方法是:我们可以只往前看到出现过的组合为止。
- 一种解决方法是:我们可以用平滑技术,猜测未知组合的概率。
- 小说库越大,预先储存【所有出现过的n个字组合】的概率,就越耗费储存空间,查询速度也慢。
就算我们解决了这些问题,这样的电脑最终也只是个背诵专家,它的创造力很低。
电脑甚至无法学会引号和括号和书名号需要配对这样的规则。电脑更无法根据前文的内容进行推理。
所以,模型需要用更复杂的算法,分析整个前文,更精确地计算出下一个字的概率分布。
以 GPT 为代表的神经网络语言模型,它的计算过程更复杂,最终电脑的理解力明显更高。
在本系列的下一篇,我将开始深入介绍 GPT 的运作细节。