深度学习与应用:百度AI平台使用浅谈
最近因为对文本情感分析有一些需要,所以去学习使用了一下百度的NLP处理模块,特此记录一下,来和大家一起分享。
最近因为对文本情感分析有一些需要,所以去学习使用了一下百度的NLP处理模块,特此记录一下,来和大家一起分享。
一:注册使用
1:如何使用百度AI
首先打开http://ai.baidu.com/,注册账户就可以
注册之后,在控制台创建应用即可
注册完成之后,进入管理应用界面:

记录好你的APPID API KEY和Secret Key,到现在,我们就可以根据文档进行搭建了
二:搭建使用环境
在这里我最初的构想是通过图片识别文字然后进行翻译再去进行句法的情感分析(中英文)
图片识别也是用的百度AI平台的OCR识别,操作与上述类似,而翻译因为我们只是做一个demo,并不需要做大批量调用,因此就用爬虫写了一个小程序,爬取一下结果。
1:图片OCR识别部分:
主要的调用大家可以参考文档,这里我们就简单用正则化匹配了一下OCR识别的结果,因为OCR识别后是Unicode编码,因此我们需要将其编码转换为汉字,就进行了一点简单的工作:
代码如下:
fromaipimportAipOcrimportjsonimportre定义常量APP_ID=11544238API_KEY=lFvnCoBOpMOtvituDObXUHt7SECRET_KEY=‘************************’初始化AipFace对象aipOcr=AipOcr(APP_ID,API_KEY,SECRET_KEY)读取图片filePath="D:\est5.JPG"defget_file_content(filePath):withopen(filePath,rb)asfp:returnfp.read()定义参数变量options={detect_direction:true,language_type:CHN_ENG,}调用通用文字识别接口result=aipOcr.basicGeneral(get_file_content(filePath),options)word=json.dumps((result))relu=r"\\u[A-Za-z0-9][A-Za-z0-9][A-Za-z0-9][A-Za-z0-9]"patter=re.compile(relu)final=patter.findall(word)i=1list1=[]foriinrange(len(final)):word=final[i]translate_final=eval("u%s"%word)list1.append(translate_final)list_add=.join(list1)拼接完成文档print(list_add)2:情感分析部分
这一部分只是百度NLP开放的一部分,比如分词,DNN语句分析,调用都比较容易,对于一句话的情感分析,改天写一篇文章细说,这方面我认为百度这个api做的还是不够好,准确程度有一些问题,并且英语汉语的感情分析会差别特别多,有些话汉语就是正向的,翻译成英语大概率就是消极的,并且可信度也比较低。
代码如下:
from aip import AipNlp
import AioOcr
import re
import Ai_translate
APP_ID = 11546514
API_KEY = bhNPuskioT4cSg7AFFYDcK9r
SECRET_KEY = ‘************************’
client = AipNlp(APP_ID, API_KEY, SECRET_KEY)
text = AioOcr.list_add
text2 = Ai_translate.ret
emotion_handle = client.sentimentClassify(text)
emotion_handle2 = client.sentimentClassify(text2)
情感倾向分析
word = client.sentimentClassify(text)
relu = r"0\.\d+"
patter = re.compile(relu)
final = patter.findall(str(word))
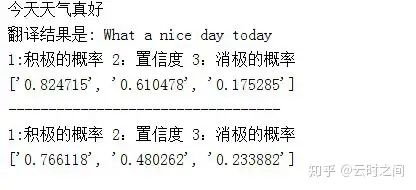
print("1:积极的概率 2:置信度 3:消极的概率")
print(final)
英文情感倾向分析
word2 = client.sentimentClassify(text2)
final2 = patter.findall(str(word2))
print("----------------------------------")
print("1:积极的概率 2:置信度 3:消极的概率")
print(final2)3:翻译部分
这一部分大体结构和我之前的百度翻译爬虫基本类似,有兴趣的可以翻阅下之前的文章:
代码如下:
import requests
import json
import AioOcr
这个网址就是百度翻译将页面的数据传送到后台的网址
url = "http://fanyi.baidu.com/basetrans"
百度翻译用来发送数据的data格式
data = {
"query": "你好世界",
"from": "zh",
"to": "en"
}
headers = {
"User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 9_1 like Mac OS X) "
"AppleWebKit/601.1.46 (KHTML, like Gecko) Version/9.0 Mobile/13B143 Safari/601.1"
}
chinese_str =AioOcr.list_add
data["query"] = chinese_str
发送post请求,把内容传送给百度翻译,并获取得到的内容
response = requests.post(url, data=data, headers=headers)
设置response的编码
response.encoding = "utf-8"
html_str = response.content.decode() json字符串
将json转换为字典
dict_ret = json.loads(html_str)
ret = dict_ret["trans"][0]["dst"]
print("翻译结果是:", ret)三:结果
1:测试1

2:测试2
四:一些想法
最近出去实验室去实习了,才发现自己在学校里学的知识和实际应用的差太多,发现自己也有些空纸上谈兵,以后自己也需要多多改正这一点。最后还是希望大家多多去公司实习,让自己变得更厉害^_^

