AI绘画零基础如何学习?
注:回答里的内容在另一个链接有更新
Dr.Rain:AI绘画教程:从入门到放弃(xiaobai)

以下内容参考了网上许多教程、感谢各位大神的无私分享,包括但不限于:
微博
,早期我了解到 DISCO DIFFUSIO,就是在阿文这。他也整理过许多AI绘画的教程,我觉得值得大家去关注一波的。B站@秋葉aaaki,分享的整合包和启动器,大大减轻所有人入门门槛!这简直是电子佛祖、朋克观音!就算不给一键三连,给个关注都不过分!

1.离线安装
1.1.离线安装包
因为后面需要更新,可以直接下载解压后不管,然后将启动器放进来。
这篇文章一开始只是我个人语雀知识库存放的,就是私底下发给一些朋友。
现在公开的话,下载链接我直接放出来有点不道德,如果失效了我也不重新放了。
大家还是去关注秋大B站吧,私信可以获取提取码,电子菩萨值得拥有。
(秋大好像取消了分享链接并关了视频留言,是发生什么事了吗?)
1.2.启动器下载
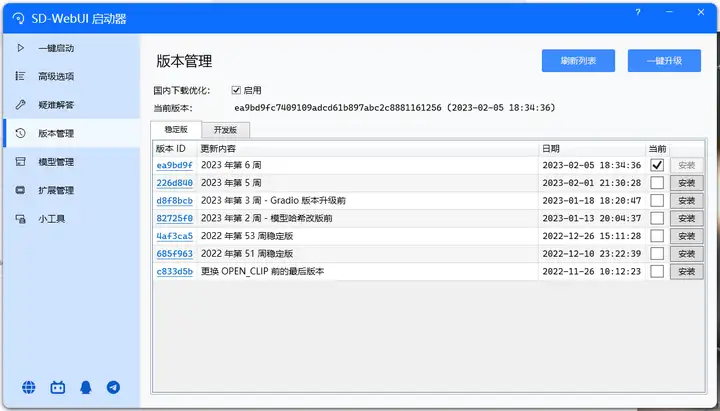
使用启动器后,让版本管理、模型管理变得更加简单,大大降低更新门槛。
1.3.WEBUI使用方式
打开WEBUI方式很简单,就是在一键启动那里点一下就可以。
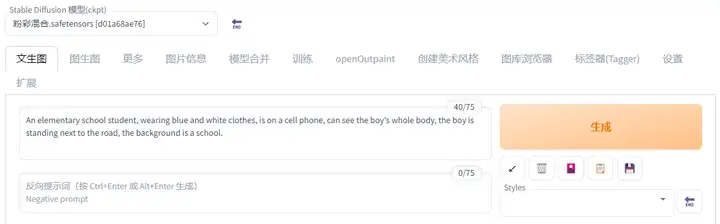
使用方法也不难,下载完就能马上体验。
基本上网上看到的教程都会有说到怎么使用。
恭喜你,你已经学会使用WEBUI,你可以开始创作获奖作品啦!开个玩笑。
想玩得更好,除了关键词的技巧外,还需要很多新的拓展、模型来配合。
后面我就把我摸索的东西都分享一下。
2.拓展包推荐
拓展包好多,好多功能得一点点试。
我想找详细的拓展包功能介绍,目前没有特别全,有需要的可以自己点开看看。
我就直接介绍我自己用得比较多的插件了。
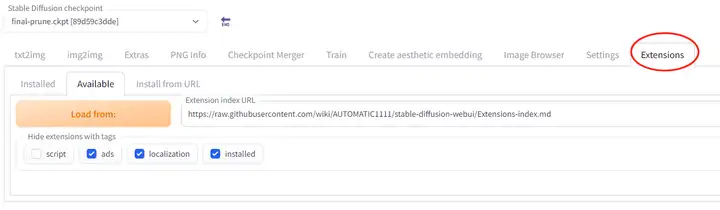
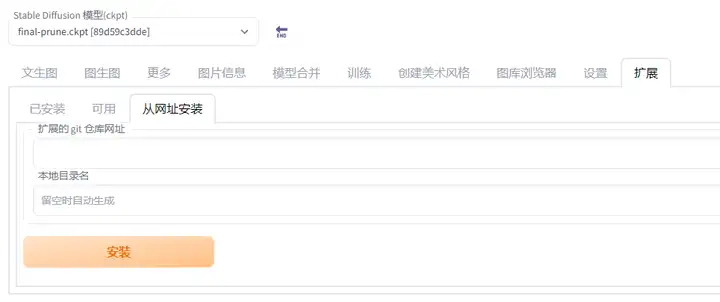
2.1.拓展的下载方式
有两种安装方式,一般直接在清单里都能找到,点一下就能安装。
2.2.汉化包
https://github.com/dtlnor/stable-diffusion-webui-localization-zh_CN
更新后会出现汉化不见的情况,可以更新汉化拓展,有三种安装方法。
2.2.1. Install from URL(从网址安装)
我自己清单里是没有这个汉化包的,复制上面的网址然后安装即可。
2.2.2. Avallable
如果你可以在扩展一栏找到这个汉化插件,直接点击 Install 。安装后重开应该就可以恢复汉化了。
2.2.3. 离线包
如果无法访问 github,则需要下载本地汉化包下载链接
下载后解压,放在extensions文件夹里面,重开就可以了。
2.3.Instruct-pix2pix
可以使用自然语言关键词修改局部画面,代替 inpating 。
但是目前没办法调用第三方模型,实际使用还是不如inpating。
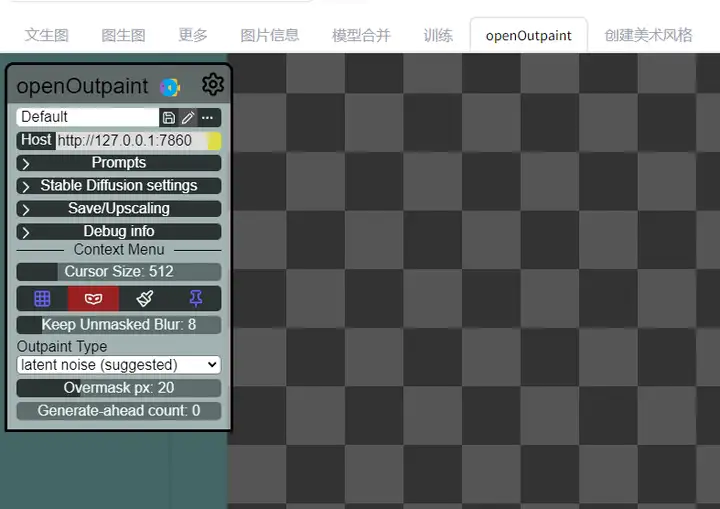
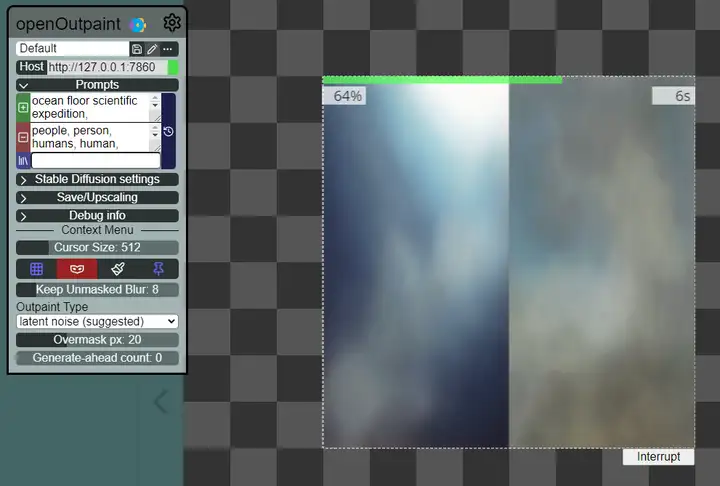
2.4.openOutpaint
这个插件主要可以根据已有画面进行拓展绘画,神器。
如果你可以正常访问github,可以在扩展一栏找到 openOutpaint extension 插件,直接点击安装后重开应该就可以了。
注意:此拓展需要开启API模式(启动器中可以勾选)
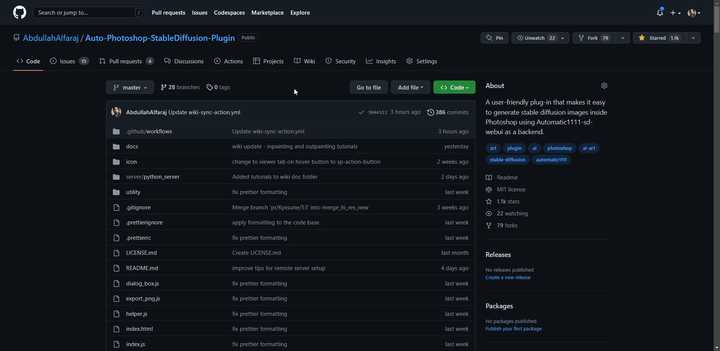
2.5.Auto-Photoshop-StableDiffusion-Plugin 【更新:2023.03.10】
https://github.com/AbdullahAlfaraj/Auto-Photoshop-StableDiffusion-Plugin
这个插件效果是可以从Photoshop中使用Automatic1111 Stable Diffusion,效果和上面差不过。
但重点是!!!这个可以在PS中使用啊!这是什么概念!效率神器啊!
SD-安装
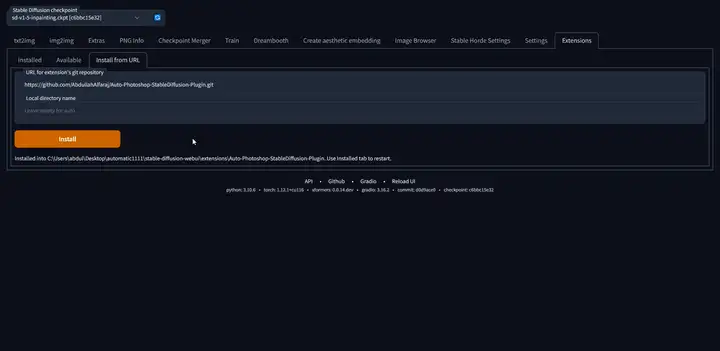
PS-安装
Creative Cloud Desktop下载地址
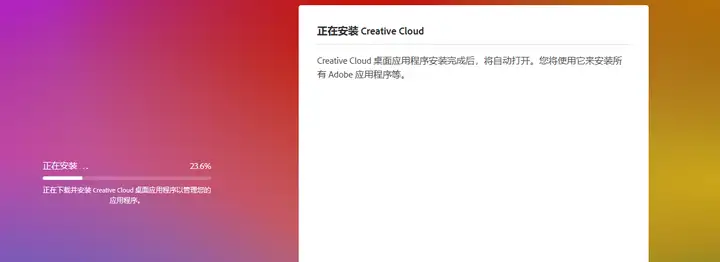
ccx增效工具下载地址
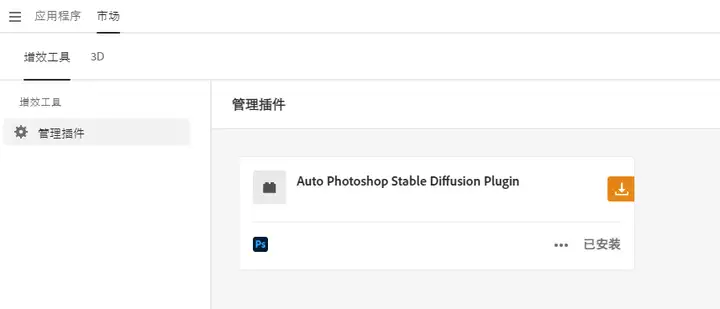
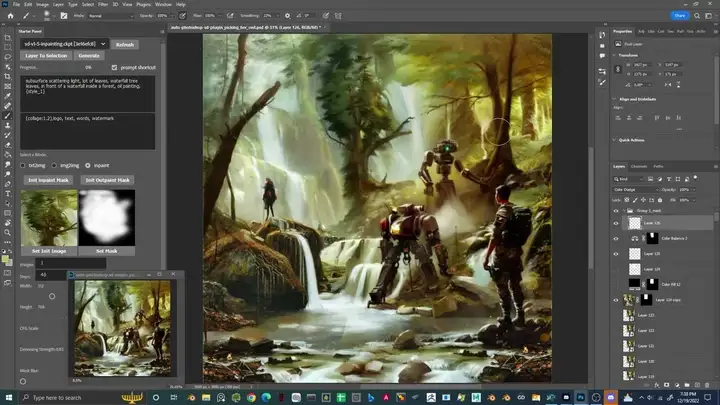
具体使用方法和WebUI没什么区别,主要可以不同两个软件换来换去啦!
2023.03.10 更新:插件可以使用controlnet
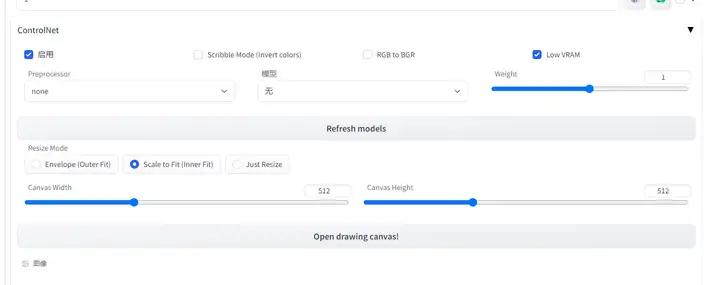
2.6.Controlnet 扩散控制网络
我觉得CONTROLNET 和 LORA,真的让AI绘画有很大的改变。
ControlNet是一种基于控制点的图像变形算法,主要用于数字图像处理、计算机视觉和计算机图形学等领域。此外,它还可以根据给定的控制点对图像进行非线性变形,从而实现对图像的精确控制和调整。
GitHub - Mikubill/sd-webui-controlnet: WebUI extension for ControlNet
https://civitai.com/models/9251/controlnet-pre-trained-models【预处理模型已出修剪版】
2.6.1.安装方法
这几天我看作者基本每天都更新…直接在拓展列表找到安装可以保证最新版。
a.拓展栏下载
可以在拓展一栏找到 sd-webui-controlnet 插件,直接点击安装后重开应该就可以了。
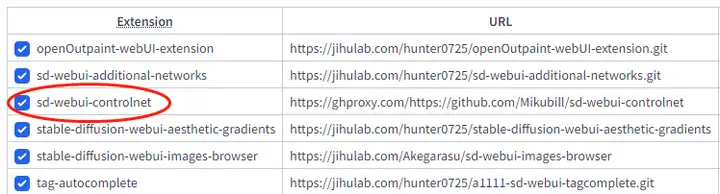
b.下载离线包
出现这种情况就会麻烦一点了
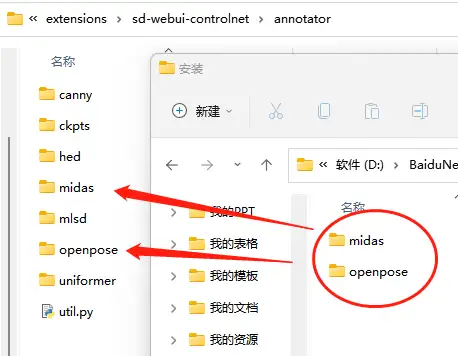
2.6.2.预处理包
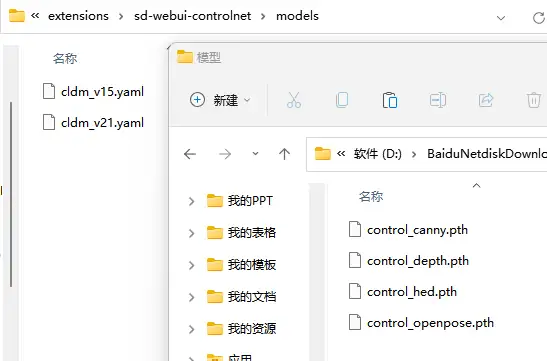
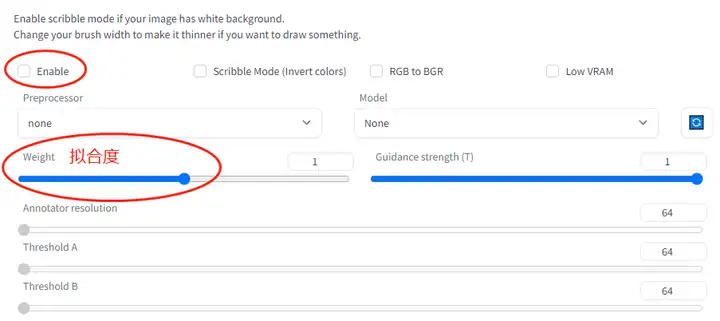
注:拟合度越大和原图原一致,但可能也会导致图片模糊。
2.6.3.预处理介绍
截止至2023.03.12,共有15个预处理器。
Canny硬边缘检测

Hed软边缘检测

Depth深度信息估算

OpenPose姿态检测
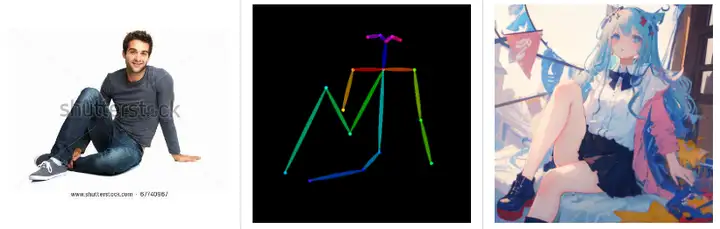
M-LSD线条检测

Scribble涂鸦
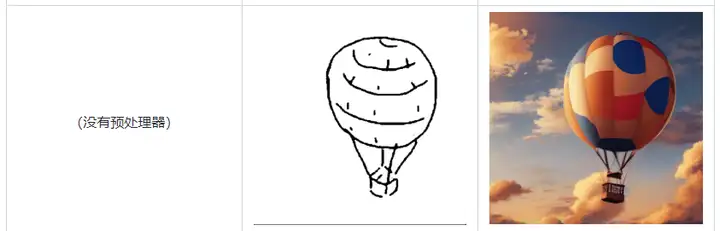
ADE20K语义分割
oneformer:https://huggingface.co/spaces/shi-labs/OneFormer

Color颜色选取器

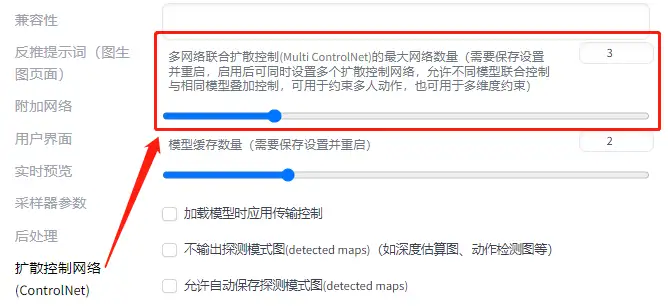
2.6.4多个 ControlNet 联合调节 / Multi-ControlNet
在设置 - 扩散控制网络 (ControlNet) - 多网络联合扩散控制 (Multi ControlNet) 中,设置多个控件。
请注意,需要重新启动 WebUI 才能使更改生效。

2.7.LoRA插件
先普及一个概念:微调。
拿ai绘画来说,就是我现在有一个模型可以画出东西但不够好,我希望在原有的基础上叠加一些东西得到更好的结果,这就是微调。微调也可以保存成单独文件单独使用,也可以和原有的模型直接合并形成一个更大的模型,从具体层面来说,这种微调可以是修改画风、画出指定的人物等等,这些操作都俗称炼丹。
lora 完整写法是Low Rank,是微软提出的一个用来进行优化大模型微调的算法,然后有人把这个算法搬到AI绘画上。同样属于微调的还有文本反演。
2.7.1.安装方法(旧)
注:
新版本 WebUI 已经自带 LoRA,旧本版需要安装。
新版本模型直接放到 novelai-webui-aki\models\LoRA 里就可以了。
将下载好的模型放入 extensions\sd-webui-additional-networks\models\lora 文件夹后,
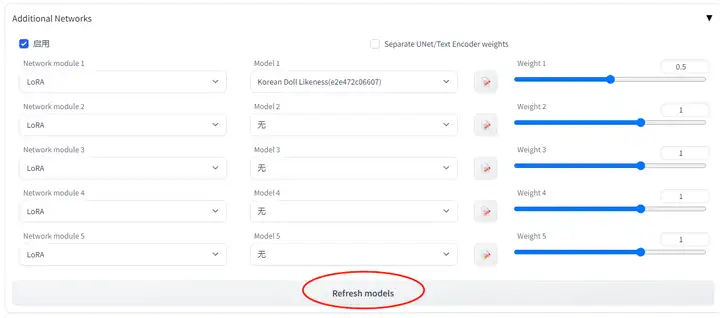
2.7.2.使用教程(旧)
在 Additional Networks 里,选择想使用的LoRA模型,可以同时使用多个LoRA模型。

2.7.3.LORA模型推荐
市面有好多LoRA模型,直接到C站可以下载
我这边选了一些代表,主要想表达的是在不改变大模型的情况下,能通过LoRA来修改风格。而更关键的是,我们是可以自己进行训练的,自己的画风、自己画的人物、自己的照片…以下模型仅作为代表。模型的训练在文末会讲述。
风格类
墨心+疏可走马:https://civitai.com/models/12597/moxin
CFG范围将会改变风格1~3大小写意 3~7逐渐工笔
推荐基础模型为国风3.2( GuoFeng3.2 ),《墨心》推荐权重为 0.85 以下,《疏可走马》推荐权重为 0.7~1。

| Trigger Words | SHUIMOBYSIM ,WUCHANGSHUO,BONIAN,ZHENBANQIAO,BADASHANREN |
前景龟背竹:https://civitai.com/models/12733BiliBili@Moeark
展示的图片大部分使用了AbyssOrangeMix3 (AOM3),训练LORA使用了anything-v4.5,推荐权重:0.3~0.8。
前景龟背竹V11是用背景都扣除NPG训练,这样对其他tag影响要小一点,但需要加一点背景描述,不然可能出现白底。

| Trigger Words | PLANT, TREE, FLOWER, GRASS, BUSH, POTTED PLANT, FLOWER POT, BROADLEAF PLANT |

| Trigger Words | DOORTOINFINITY |
Flonix MJ Style :https://civitai.com/models/6733/flonixmjstylelora300

| Trigger Words | / |
扁平化:https://civitai.com/models/6326/luisapcute-flat-color-lineart-lora

| Trigger Words | / |
Maplestory:https://civitai.com/models/14313/maplestory-style
当与其他 Lora 结合使用时权重为0.7-0.8

| Trigger Words | CHIBI |
CuteScrap:https://civitai.com/models/5100/cutescrap-05v

| Trigger Words | WRAL |
未研究 | 明朝汉服未研究 | 国风篇
二次元类
卡通:https://civitai.com/models/5126/torino-aqua-style-lora
我建议 Anything V4.5 或深渊橙色 V2 上的偏移版本的权重为 1,旧版本为 0.6。

| Trigger Words | TORINO AQUA |
SamDoesArts (Sam Yang) Style :https://civitai.com/models/6638/samdoesarts-sam-yang-style-lora

| Trigger Words | SAM YANG |
国王的排名:https://civitai.com/models/6327/ousama-ranking-style-lora
Trigger Words:OUSAMARANKING STYLE

龙珠:https://civitai.com/models/4857/akira-toriyama-style-lora

海贼王:https://civitai.com/models/4219/one-piece-wano-saga-style-lora

真人类
韩国妹子:https://civitai.com/models/7448/korean-doll-likeness
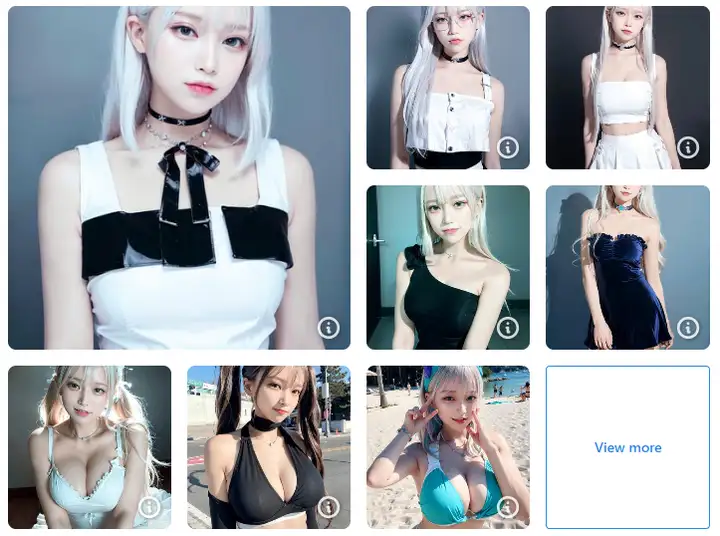
| Trigger Words | WOMAN GIRL |
Yae Miko:https://civitai.com/models/8484/yae-miko-or-realistic-genshin
所有样本均使用Ulzzang-6500嵌入vae-ft-mse-840000VAE生成。 推荐权重为 txt2img - 0.45-0.75,较高的权重可能会导致面部生成不良。

| Trigger Words | yae_sakura |
杨超越:https://civitai.com/models/10966/cngirlycy

| Trigger Words |
狗头萝莉:https://civitai.com/models/12030/goutou-lora

| Trigger Words | GOUTOU |
老白:https://civitai.com/models/14156/walter-white-bryan-lee-cranstonlora

| Trigger Words | A MAN, BALD, WEARING GLASSES, WEARING, SUNGLASSES, WEARING A HAT |
2.8.Deforum 动画插件
https://github.com/deforum-art/deforum-for-automatic1111-webui
官方使用指南:Quick Guide to Deforumv05
数学关键帧函数指南:MATHs in Deforum v05
2.8.1.安装方法
依赖:
3D模式需要依赖
导出MP4需要安装FFMPEG
跟踪动画进度,需要激活IMAGE CREATION PROGRESS
2.8.2.使用方法
3.大模型(底模)推荐
底模的大小比较大,常见是4G左右,也有一些2G、8G左右的大模型。
不同的底模就决定了出来图片风格是怎么样的,NovelAI、Anything 这些都是比较知名的二次元底模,然后还有就是近期很火的真人底模 ChilloutMix。需要注意的是,部分模型有写需要对应的 VAE 滤镜,下载好放目录就可以了。
3.1.模型社区CIVIT AI

存放地址:models\Stable-diffusion
3.2. 拟真类
真实相片
https://civitai.com/models/4201/realistic-vision-v13
关键词:RAW photo, *subject*, (high detailed skin:1.2), 8k uhd, dslr, soft lighting, high quality, film grain, Fujifilm XT3
Negative Prompt:(deformed iris, deformed pupils, semi-realistic, cgi, 3d, render, sketch, cartoon, drawing, anime:1.4), text, close up, cropped, out of frame, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck
梦幻逼真
https://civitai.com/models/3811/dreamlike-photoreal-20
Warning: This model is horny! Add "nude, naked" to the negative prompt if want to avoid NSFW.

意大利风情
https://civitai.com/models/5131/italian-style

ChilloutMix
https://civitai.com/models/6424/chilloutmix
同作者衍生模型:Sunshinemix
If you like more smaller tits, try both of prompts,"(small breasts) and (fantasy breasts)" (Slim girl) maybe good.

梦幻卡通风
https://civitai.com/models/5041/cheese-daddys-landscapes-mix

3.3. 二次元类
动漫卡通
https://huggingface.co/gsdf/Counterfeit-V2.5
https://civitai.com/models/4468/counterfeit-v25
粉彩混合
https://civitai.com/models/5414/pastel-mix-stylized-anime-model
Sampler:DPM++ 2M KarrasSteps:20CFGScale:7Hires. Fix:OnUpscaler:Latent (MUST!)Hires Steps:20Denoising Strength:0.

深渊橙混2
https://civitai.com/models/4437/abyssorangemix2-sfw

Xpero End1ess Model
https://civitai.com/models/6231/xpero-end1ess-model

Samdoesarts Ultmerge
https://civitai.com/models/68/samdoesarts-ultmerge

法式风
https://civitai.com/models/5396/dalcefov3painting
strongly recommand "realistic" prompt

anything V4.0:视频教程
3.4. 风格类
剪纸风
https://civitai.com/models/80/midjourney-papercut

给他爱5
https://civitai.com/models/1309/gta5-artwork-diffusion

日漫
https://civitai.com/models/1484/ranmadiffusion

Hollie Mengert 风格
https://civitai.com/models/81/hollie-mengert-illustration-diffusion

Inkpunk Diffusion
https://civitai.com/models/1087/inkpunk-diffusion

4.提示词
关于这方面已经有许许多多的人都做了教程,可慢慢研究:
https://kdocs.cn/l/cj4WVY2PCX2B
魔咒指南:https://kdocs.cn/l/ckgWD4Qreu2F
AI绘画——深度教程:https://docs.qq.com/doc/DQ3ZJSGFmeVpWc2ta
Tags基本编写逻辑及三段术式入门与解析v3:https://docs.qq.com/doc/DSHBGRmRUUURjVmNM
元素法典:https://docs.qq.com/doc/DWHFOd2hDSFJaamFm
4.1.提示词的分类
4.1.1.prompt关键词的种类和定义
Format 图片格式:照片、油画
Subject 主题词: 机器人、兔子、星球
Solidifier 巩固主题词细节:战争机器人、兔子在树洞里、星球伴随着卫星
Perspective 观察视角:透过窗、从顶视角
Artist 艺术形式:达芬奇风格、赛博朋克风
Style 必填风格:日本动漫风
Vibe 氛围或情绪:平静、自然光
Booster 质量推进词:8K像素、高度细节
Weights 排除(--没有树)混合(抹茶色:75 克力色:25)

Prompt Template:
[format 图片格式] of [subject term 主题词], a [solidifier 巩固主题词细节], [perspectivel 观察视角], by [artist:75] | by [artist:25], in the style of [style], [vibe],[booster],[exclusion]
e.g.
Photograph of a rabbit , a rabbit in space, through atelescope, by Leonardo da vinci:75 by pablo picasso:25, in the style of cyberpunk, cinematic, 4k resolution, --nooutline
4.2.文本反演
这个功能大家说得比较少,在网上找了一番,(g.nga.cn社区)有大佬解释就是:
文本反演是试图将图片中的抽象概念直接转译成机械语言(向量),然后再把这个机械语言与某个词汇关联起来。
简单说就是创造出一个新的提示词然后算这个提示词对应图像的最优解。反正我理解就是,用某个特定提示词 A 打包了一堆某种画风的提示词 a/b/c...,使用时就通过固定提示词 A 把这些提示词 a/b/c... 解压出来,节省了写这些关键词的步骤。
文本反演和LoRA一样,属于模型的微调,因此尽可能选用贴合你需要风格的底模再使用相关提示词。
使用方法
- 下载文本反演包
- 将下载好的文件放进 embeddings 文件夹里
- 在填写提示词时,填上触发文本反演的提示词
原神风
https://civitai.com/models/6841/adventure-diffusion
Trigger Words:ADVNTR

美漫风
https://civitai.com/models/6543/old-fashioned-diffusion
Trigger Words:OLFN

赛博朋克
https://civitai.com/models/6016/neon-diffusion
Trigger Words:EONN

墨水朋克 Inkpunk
https://civitai.com/models/1288/inkpunk768
Trigger Words:INKPUNK768

赛博朋克-机甲:
https://civitai.com/models/2289/psycho-style
Trigger Words:STYLE-PSYCHOSTYLE-PSYCHO-NEG
4.3.利用文本反演填写负面提示词
https://huggingface.co/datasets/gsdf/EasyNegative
https://huggingface.co/datasets/Nerfgun3/bad_prompt
[SD1.5] Deep Negative V1.x
https://civitai.com/models/4629/deep-negative-v1x
[SD1.5] badquality - Negative Embedding
https://civitai.com/models/19968/badquality-negative-embedding-for-wd15
[SD1.5] 动漫负面提示
https://civitai.com/models/15287/7-dirty-words-negative-prompt
[SD1.5] 坏的艺术家
https://civitai.com/models/5224/bad-artist-negative-embedding
[SD1.5] 真人负面提示-Chilloutmix
https://civitai.com/models/17083/bad-picture-negative-embedding-for-chilloutmix
[SD2.1] 真实性负嵌入
https://civitai.com/models/4044/doctor-diffusions-point-e-negative-embedding
5.【高阶】LoRa模型训练
GIt:https://git-scm.com/download/win
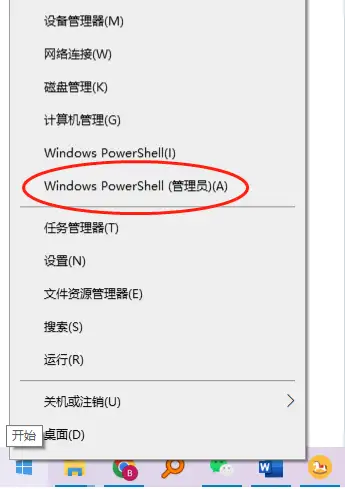
下载安装玩上面的GIT包,然后打开PowerShell的管理员模式。
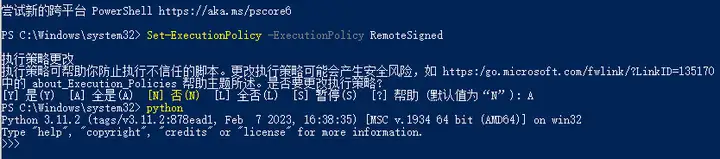
输入 Set-ExecutionPolicy Unrestricted,更改策略为A,完成后关闭 PowerShell。
5.1.a.秋叶一键包的安装教程
https://pan.baidu.com/s/1PaMKUd8l-dsurgaEDYsxtg?pwd=qx83
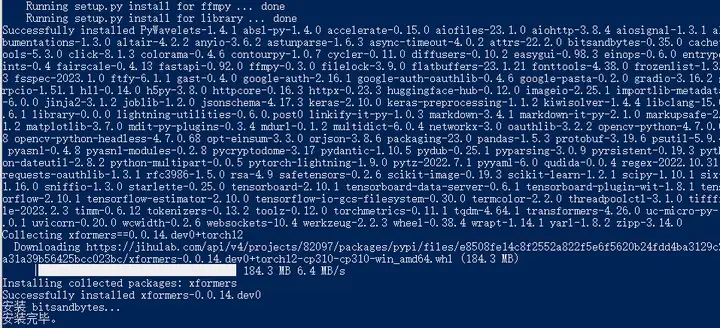
我在家里这个步骤一直报错,找了很多方法,一直安装不成功,公司电脑则完全没有问题。结果第二天回到家再试一次,又没有问题了…可能和操作系统版本不一样有关?家里WIN10,公司WIN11。
5.1.b.kohya_ss GUI的安装教程
炼丹炉:https://github.com/jonathanzhang53/kohya_ssinstallation
kohya_ss GUI :数据集创建和准备kohya_ss GUI :模型训练
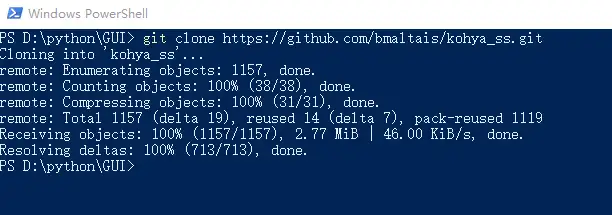
一行一行输入下面代码。
git clone https://github.com/bmaltais/kohya_ss.git
cd kohya_ss
python -m venv venv
.\venv\Scripts\activate
pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 --extra-index-url https://download.pytorch.org/whl/cu116
pip install --use-pep517 --upgrade -r requirements.txt
pip install -U -I --no-deps https://github.com/C43H66N12O12S2/stable-diffusion-webui/releases/download/f/xformers-0.0.14.dev0-cp310-cp310-win_amd64.whl
cp .\bitsandbytes_windows\*.dll .\venv\Lib\site-packages\bitsandbytes\
cp .\bitsandbytes_windows\cextension.py .\venv\Lib\site-packages\bitsandbytes\cextension.py
cp .\bitsandbytes_windows\main.py .\venv\Lib\site-packages\bitsandbytes\cuda_setup\main.py
accelerate config5.2.安装时出现的报错
5.2.1.无法将.\venv\Scripts\activate项识别为 cmdlet、函数、脚本文件或可运行程序的名称。
解决思路:
看看是不是有python的其他版本? 我之前做有个软件需要安装3.7.7版本,删除后就没有问题了。
5.2.2.torch安装失败,请删除 venv 文件夹后重新运行。
解决思路:
看看是不是有python版本是不是太新了?目前程序还不适应新版python.

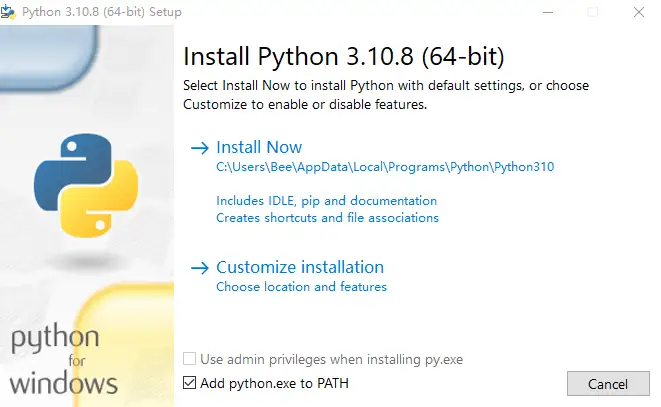
安装旧版本 3.10.8 即可,小版本差别也有可能报错,我卸载重装后没报错了。
下载链接:https://python.org/downloads/release/python-3108/
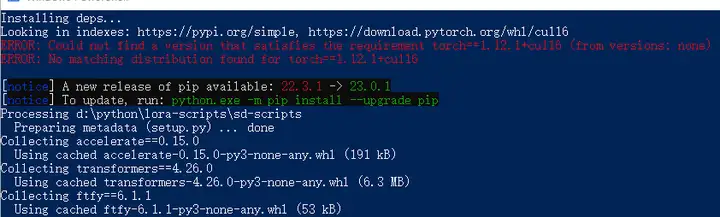
5.2.3.No matching distribution found for torc==1.12.1+cu116
解决思路:
同样先确认python版本有没有差别,我发现很大概率都是这个问题。
5.2.4.WARNING: pip is being invoked by an old script wrapper. This wil1 fail in a future version of pip.
解决思路:未解决
之前遇到过的警告,不知道有什么影响没…反正我后来删掉所有东西重新安装是没有警告了…

5.3.图片预处理
裁剪图片:建议裁剪为512*512,并扣除复杂的背景。
打tags:生成说明文字
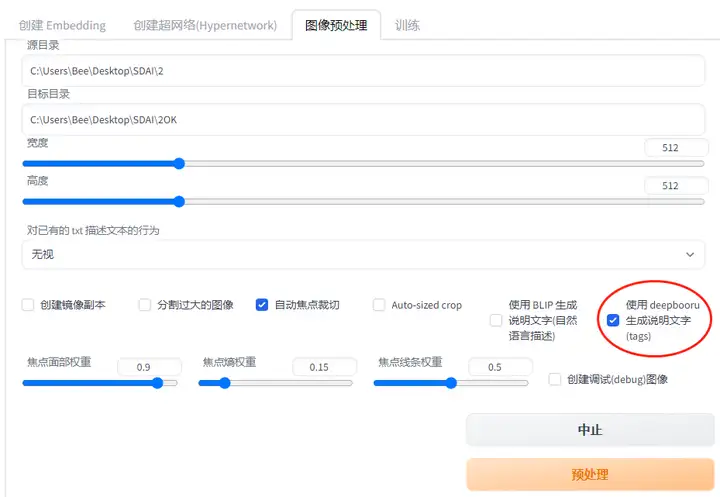
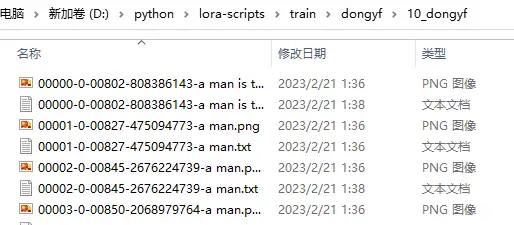
然后将处理好的图片和关键词放入文件夹train中
5.4.预处理时会出现的报错
1.Error verifying pickled file from
解决思路:
这个错误信息的意思是,在加载模型文件时发生了错误。具体来说,是因为该文件在读取时出现了异常。异常的原因可能是该文件已损坏。此外,还提示可以使用--disable-safe-unpickle命令行参数来跳过检查。但是,这不会解决损坏的文件问题。
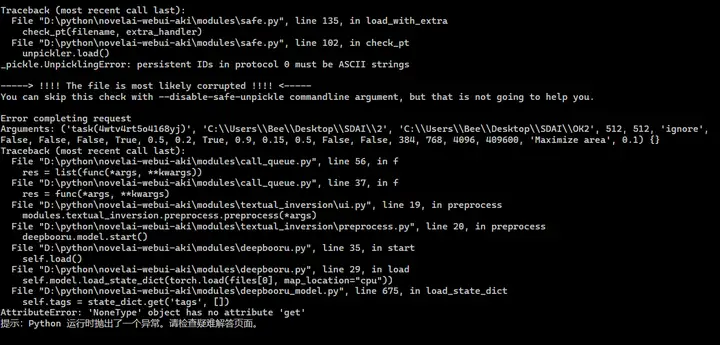
【成功方法】在 webui-user.bat 文件的 set COMMANDLINE_ARGS= 文本后面添加 --deepdanbooru 参数,然后需要重新启动 webui。https://bilibili.com/read/cv19567250/
【无效方法一】如果遇到类似Bad File Error verifying pickled file from … 之类的错误,打开webui-user.bat,在set COMMANDLINE_ARGS=后面添加上 --disable-safe-unpickle (包含空格),然后重启stable-diffusion(实测无效)
【无效方法二】modules\shared.py 第83行 default=True(实测不行,会产生新的报错)
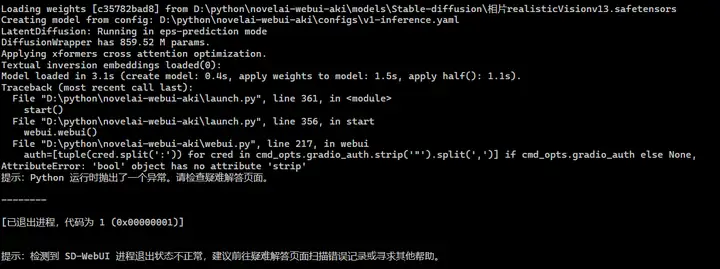
【无效方法三】重新下载模型文件离线包(无效)
5.5.修改 train.ps1 参数
直接将模型复制进 \lora-scripts\sd-models 文件夹内。
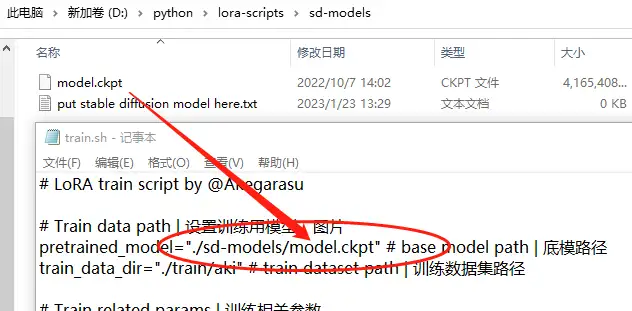
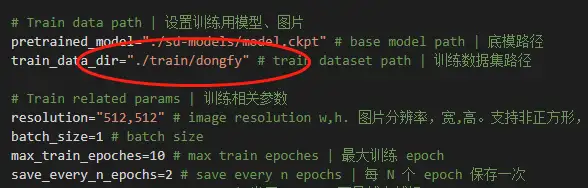

保存train.sh参数后,右键 train.ps1 使用 PowerShell 运行即可。
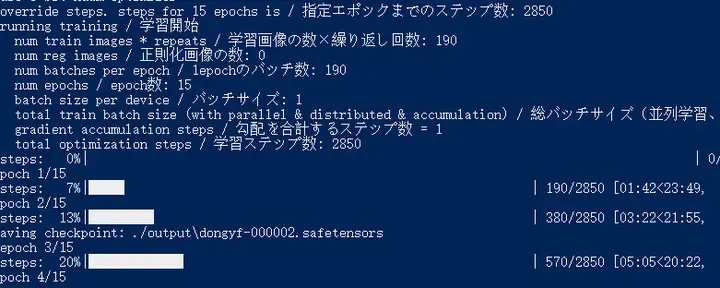
5.6.训练时出现的报错
For effortless bug reporting copy-paste your error into this form:
【成功方法】点击训练文件夹里的强制更新,更新后重新设置 train.ps1 内的参数即可。

【无效方法】train_unet_only 的参数 0 改为 1
【无效方法】在训练代码里面删掉 --xformers --shuffle_caption --use_8bit_adam $ext_args 就行了
5.7.炼丹技巧
整理标签方法:1.去除想要模型记住的特征 2.添加没有被识别到的非人物特征标签
被标注的词条 (tag)不会被 LORA 模型记住。训练中 LORA 会把没被标注的词条当做默认元素,这与训练 textualinversion (embedding 模型) 是完全相反的,因此在准备数据时需要删除与想要实现的效果相关的词条。
人物模型:
想要一个更精确的人物模型就需要去除人物生理特征和外观特征的词条;只保留画面特征(画面构成、角度、动作等)。如果自动识别没有识别到某些画面特征,最好手动整理输入。素材图片最好是头像、全身像、侧身像、背身像兼具。为了增强人物对应多种画风的手段,最好能整理不同画风的人物;如果想要尽可能复刻人物的画风,则可以尽量统一画风。
风格模型:
画风风格很难用词条形容,因此画风很容易被模型学到。大部分情况下都不需要删除任何词条,因为自动识别是很难识别出画风的(如果想要训练单色模型可以删掉),除此之外的人物词条、角度词条等都要保留以及补全。
触发词
将与人物相关的词条都删去后,加入一个特定的触发词作为标签,这样在使用时不仅要导入 LORA 模型,还要输入触发词才能输出想要的结果。触发词可以在单概念模型中用处不大,但在多概念模型中非常有效。
5.8.实例:冷门角色炼丹
对于冷门角色只有一张图时,可以用单图做过拟合的LoRA训练,形成模型A。
然后利用Controlnet+模型A,生成新的图片。
最后用新的图片库做LoRA训练,即可得到并不会过拟合的模型B。
6.文本反演训练
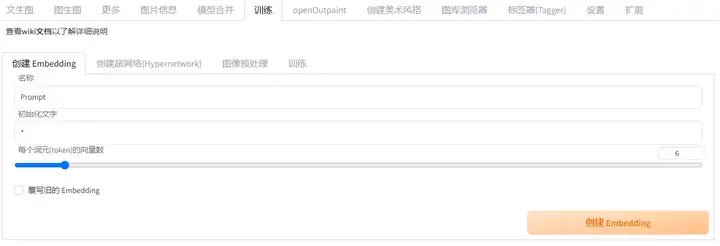
6.1.创建Embedding
第一步:不使用vae
第二步:填写参数信息
第一行为触发的 Prompt;第二行不用改;第三行是占用Prompt数,建议 2-8
第三步:创建Embedding
6.2.图片预处理
第一步:准备需要学习图片5-16张,建议30张以上。
第二步:裁剪图片为合适尺寸
一般512*512,可以自己裁剪或者直接用Train里的预处理功能
第三步:保存至同一个文件夹内
6.3.训练
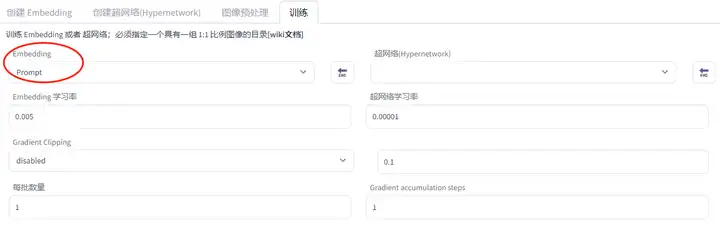
第一步:选择刚刚创建的Embedding模型
第二步:调整学习率(一般默认即可,如果希望更快一点可以调整为0.01)

第三步:修改输出目录及Prompt template (一般风格类为 style_filewords,人物类为 subject_filewords )
第四步: 根据图片数量修改所需步数,并不是越多越好,否则容易过拟合。
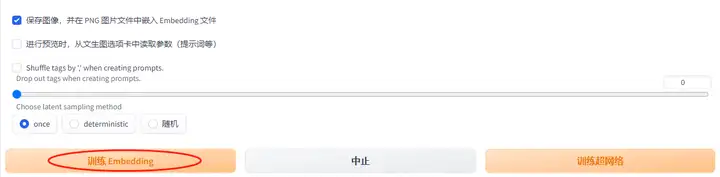
第五步:点击训练Embedding,等待生成结果即可。
————————————
2023.02.22
昨天看了一下内容,因为之前自己记录在语雀时内容比较零散。我把前面一下内容调整了一下,尽量从小白到入门到放弃的难度级别。然后补充了一个关系PS里使用SD的插件,之前归类是最后其它插件,不过想了想应该还是属于SD插件了。
这几天有点忙,我可能暂时不更新(自己用的很多内容还没截图,基本文章内容我能实操截图我都会截出来)。
我个人工作并不是设计、程序员,也是工作外自己报了某个网红课程学习了PYTHON(当冤大头),设计只是爱好向。实际很多东西都是靠各路大神分享学习来的,我也只是个搬运工罢了,希望对大家有用。
然后希望大家除了收藏外,给些赞同,我不需要像其它人那样引流公众号,但文字传播效果实在太差,而且篇幅也很长。大家给的留言点赞对系统来说就是正向反馈,可以让系统推荐给更多人看到,抛砖引玉。这些技术越多人使用,也会让技术发展得更快,距离大家畅想的未来就越近了。
————————————
7.云部署
电脑配置不好的小伙伴,可以使用云服务器>>>https://autodl.com/home
除了可以部署SD-webui,像训练LORA模型在云端就更方便了。
7.1.WEBUI
CodeWithGPU:部署教程B站视频@小李xiaolxl
7.1.1.进入JupyterLab,更新WEBUI并运行
第一步:输入以下代码,进入目录
cd stable-diffusion-webui/
第二步:查找学术加速源,并输入其代码:
第三步:输入以下代码,执行更新:
git pull
第四步:输入以下代码,执行程序:
rm -rf outputs && ln -s /root/autodl-tmp outputs
python launch.py --disable-safe-unpickle --port=6006 --deepdanbooru
如果出现下图报错情况,执行代码尾部加上【 --share】
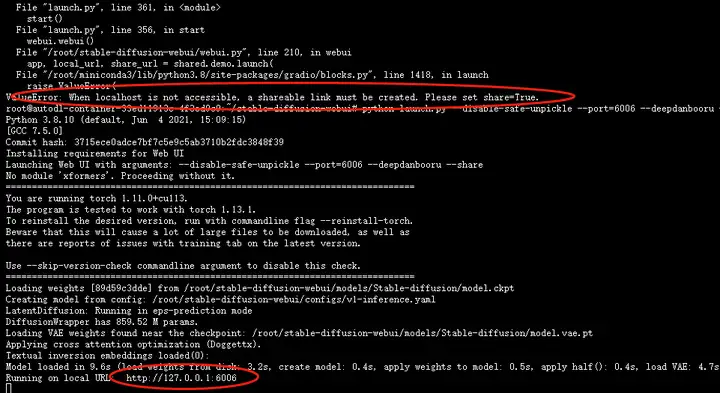
第五步:进入WEBUI
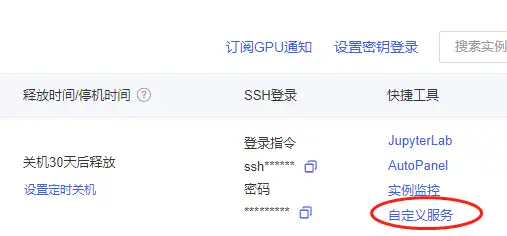
7.2.LoRA
直接在镜像搜索LoRA,就可以找到电子佛祖的训练包啦。

